
摘要:
无人机搭载的高光谱数据可以捕捉水体的精细特征,已被广泛应用于水质监测。在本项研究中,系统地评估了九种机器学习算法,用于利用无人机搭载的高光谱数据反演包括叶绿素a(Chl-a)和悬浮物(SS)在内的水质参数。在比较机器学习模型对水质参数的实验结果时,我们可以观察到Catboost回归(CBR)模型的预测性能最好。然而,多层感知器回归(MLPR)和弹性网(EN)模型的预测性能非常不理想,表明MLPR和EN模型不适合反演水质参数。此外,还生成了水质分布图,可用于识别水体的污染区域。
1、导言
叶绿素a(Chl-a)浓度和悬浮物(SS)浓度是最常见的水质参数。叶绿素a是一种典型的光学活性参数,广泛存在于藻类、蓝藻以及其他水生植物中。叶绿素a浓度是基于营养物质可用性的水体富营养化指标,量化了水体的营养状况。高浓度的悬浮物会降低水的透光率,增加可见光波长下的离水反射率。水中悬浮物的浓度也与重金属和有机物等污染物的迁移直接相关。
机器学习模型可以从数据中快速获取所需的信息,但不同的模型具有不同的特征。因此,本研究的主要目的是:(1)使用R2、RMSE和MAE等评价指标,比较和分析不同机器学习模型的预测性能,包括CBR、Adaboost回归(ABR)、极值boost回归、随机森林(RF)、极值随机化树(ERT)、支持向量回归(SVR)、MLPR和EN,(2)使用典型的水质参数,包括叶绿素a和悬浮物,来评估机器学习模型;(3)验证机器学习模型与无人机载高光谱数据相结合在水质测绘中的潜力。
2.1 / 试验区域
研究区域为广西省柳州市北弓水库(东经114°21′14.15〃,北纬30°35′5.52〃),集水面积6.8平方千米。
2018年9月9日至10日,在北宫水库统一进行了现场调查。根据现场数据采集规定,在北宫水库采集了33个采样点进行Chl-a和悬浮物反演,现场采样数据在实验室进行了分析。水样采集数据的统计信息如表1所示。北宫水库的详细信息如图1所示,其中显示了水质采样点、地下水表面光谱点、无人机飞行路线和获得的无人机飞行带。
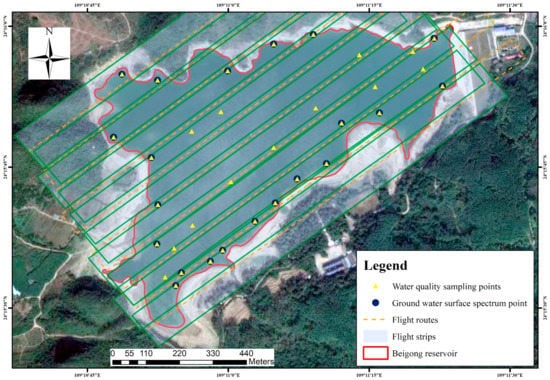
图1 研究区域和采样信息

表1 北弓水库水样数据统计信息
2.2 / 实验设备
使用地物光谱仪,获取水面光谱、天空光谱和同步参考板的光谱数据,进行离水反射率的测量。
采用六旋翼 DJ M600 Pro 无人机作为机载平台,搭载 Headwall Photonics Inc 制造的 Headwall NANO Hyperspec 高光谱传感器,光谱分辨率为 6.0 nm,采样间隔为 2.2 nm,飞行时视场角为 16°,飞行高度为 400 米,实时风速为 5.2 m/s,根据水库面积设计 10 条飞行路线,沿轨重叠 80%,侧重叠 60%,在 400 - 1000 nm 范围内有 270 个光谱带,高光谱图像空间分辨率为 0.173 m /pixel,数据预处理包括水体提取(使用归一化差异水指数 NDWI)、传感器校准、几何校正和辐射校正。
2.3 / 研究方法
机器学习算法:
1、Adaboost 回归(ABR):通过训练弱学习器并整合得到最终模型,根据预测误差率为样本分配不同权重,调整样本权重,累积所有学习器的预测结果生成预测值。
2、梯度提升回归树(GBRT):基于集成决策树的机器学习算法,通过最小化平方误差构建回归树,使用损失函数的负梯度近似当前模型预测值与观测值之间的残差,优化回归树权重,通过不断迭代得到最终预测结果。
3、极端梯度提升回归(XGBR):基于 GBDT 算法改进的决策树算法,通过不断添加和训练新的决策树来拟合前一次迭代的残差,积累所有决策树的预测值得到最终预测结果,修改了 GBDT 算法的目标函数,通过减少模型偏差提高预测性能。
4、Catboost 回归(CBR):基于梯度提升框架的新决策树算法,使用无意识决策树作为基础学习器,能高效处理分类特征,使用改进的贪婪目标统计方法添加先验分布项以减少噪声和低频数据的影响,构建新分裂节点时考虑不同类型特征的组合并动态转换为数值特征,通过有序提升代替传统算法中的梯度估计来克服预测偏移。
5、随机森林(RF):使用 bootstrap 方法从原始数据中随机选择 n 个样本构建决策树,节点分裂时使用信息增益方法从 M 个属性中随机选择 m 个属性,选择增益最大的属性作为最佳分裂属性,平均多个决策树的预测结果得到最终预测结果。
6、极随机树(ERT):结构与 RF 相似,训练过程中使用所有样本构建决策树,节点分裂时随机选择属性分裂,生成的决策树规模比 RF 大,方差比 RF 小。
7、支持向量机(SVR):基于核的算法,通过寻求最小结构化风险和实现经验风险最小化来提高模型的泛化能力,在小样本情况下能获得良好的预测结果。
8、多层感知器回归(MLPR):最常用的人工神经网络模型,由输入层、输出层和一个或多个带激活函数的隐藏层组成,使用训练集的子集调整各层节点的权重和偏差,能获取非线性关系和实时学习,但需要调整许多超参数,耗时。
9、弹性网(EN):Lasso 回归(LR)和 Ridge 回归(RR)的混合,具有 RR 和 LR 的优点,能自动选择变量并保留重要特征,消除无关特征。
模型评估:通过 R²(决定系数)、RMSE(均方根误差)和 MAE(平均绝对误差)三个指标评估模型性能。
3、结论
3.1 / 光谱分析
叶绿素a 光谱特征:在蓝(443 nm)和红(近 675 nm)处有强吸收,在绿(550 - 555 nm)和红边光谱区域(685 - 710 nm)有高反射率。
悬浮物光谱特征:监测水中悬浮固体最适合的光谱范围是 700 - 800 nm。
原始光谱与水质参数相关性:原始光谱数据与叶绿素 a 浓度值的相关系数为负相关,84 个光谱绝对相关系数大于 0.7,主要集中在 400 - 590 nm 波长范围;与悬浮物浓度值的相关系数范围为 0.1755 至 0.7685,46 个光谱相关系数大于 0.7,主要集中在 700 - 800 nm 波长范围。
波段比预处理后光谱与水质参数相关性:本研究采用穷举法计算了原始光谱的181个波段的比值,与叶绿素a 浓度值相关的12 个比值变量相关系数大于 0.81,主要集中在 400 - 480 nm 波长范围;与悬浮物浓度值相关的43 个比值变量相关系数大于 0.76,主要集中在 592 - 606 nm 波长范围。

图2无人机载高光谱遥感图像中33个水体样本的光谱曲线
3.2 / 水质参数反演结果
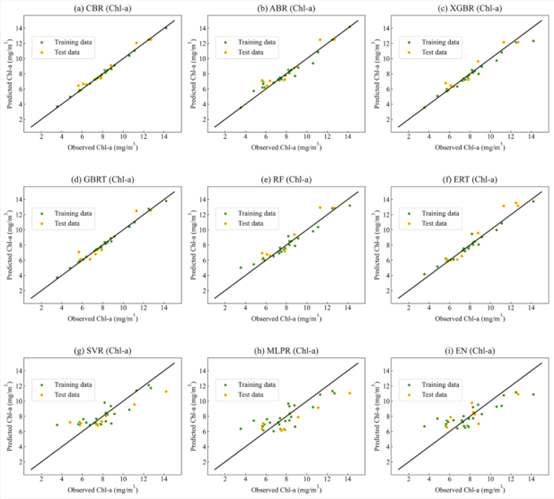
叶绿素a:CBR 模型预测性能最好,MLPR和 EN模型预测性能太差,不适合用于叶绿素a的反演。
悬浮物:CBR 模型预测性能最好MLPR和 EN模型预测性能太差,不适合用于悬浮物的反演。
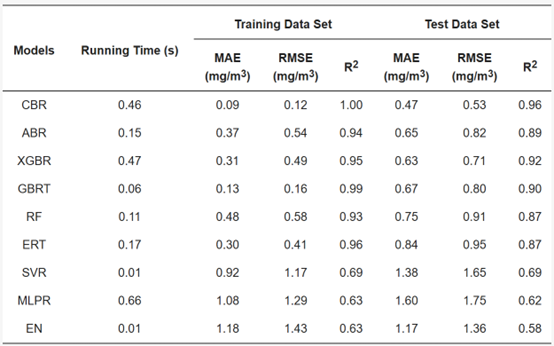
表2 不同模型下叶绿素a(mg/m3)的实验结果
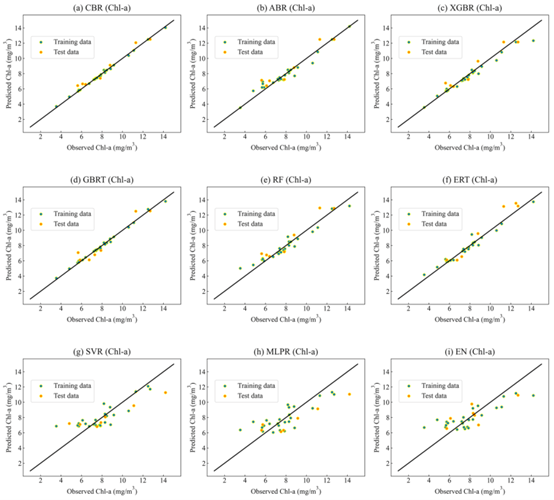
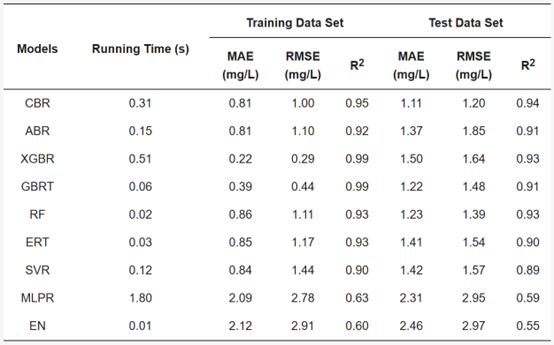
表3 使用不同模型的悬浮物(mg/L)实验结果
使用CBR模型反演北弓水库叶绿素a与悬浮物的分布地图,叶绿素a浓度在水库西部相对较高,主要集中在沿岸,水库西南部悬浮物浓度明显高于整个水库,水库边界附近有零星红斑,可能是由短暂的人类活动产生。
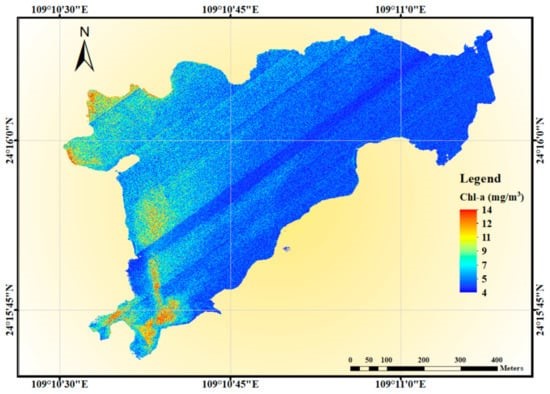
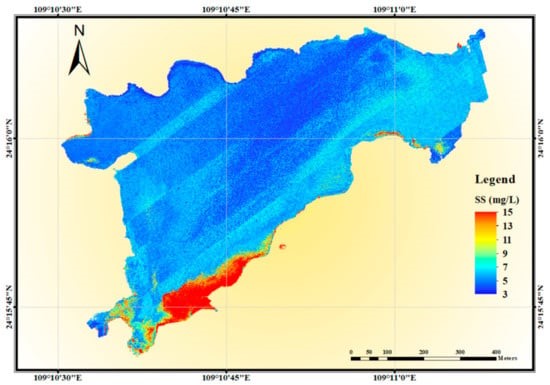
图6 悬浮物浓度分布图
4、总结
树基模型(CBR、XGBR、GBRT、ABR、ERT、RF)的总体预测精度高于其他三个传统机器学习模型(SVR、MLPR、EN)。
对于叶绿素a 的预测,CBR 模型预测精度最高,XGBR 模型次之;对于悬浮物的预测,CBR 模型预测精度最高,XGBR 和 RF 模型次之。CBR 模型在预测叶绿素a 和悬浮物等水质参数时表现稳定且令人满意。
未来,将结合多时相无人机载高光谱图像分析内陆水质的动态变化,长期监测水库水质。
原文链接:https://www.mdpi.com/2072-4292/13/19/3928